Kubernetes Nodes in Thalassa Cloud
In Thalassa Cloud, a Kubernetes Node is a virtual machine that runs workloads within a Kubernetes cluster. Nodes are provisioned automatically and managed by the Thalassa Cloud Kubernetes Control Plane based on the Kubernetes Node Pool configured.
Each node includes the following core components:
- Kubelet: Communicates with the API server and manages workloads on the node.
- Container Runtime: Runs and manages containers (Thalassa Cloud supports containerd).
- Kube-Proxy: Handles networking and service discovery within the cluster (can be disabled when using Cilium CNI).

Kubernetes Node Pool Machines
Node Types
Thalassa Cloud offers different types of nodes, depending on the workload requirements:
| Node Type | Description |
|---|---|
| General Purpose Nodes | Standard compute nodes for most workloads. |
| High-Memory Nodes | Optimized for memory-intensive applications such as databases and in-memory processing. |
| GPU Nodes | Designed for AI, ML, and GPU-accelerated workloads. |
Node Pool Configuration
Node pool autoscaling
Thalassa Cloud supports cluster autoscaling using the upstream Kubernetes Cluster Autoscaler. Autoscaling can be enabled per node pool to automatically adjust the number of nodes based on workload demand.
- Enable autoscaling on a node pool
- Configure minimum and maximum replicas; minimum can be set to 0 to allow full scale-to-zero for the pool
- The Cluster Autoscaler will increase or decrease nodes to satisfy pending Pods and underutilization, targeting the configured replica bounds
See the dedicated guide for configuration details: Node pool autoscaler.
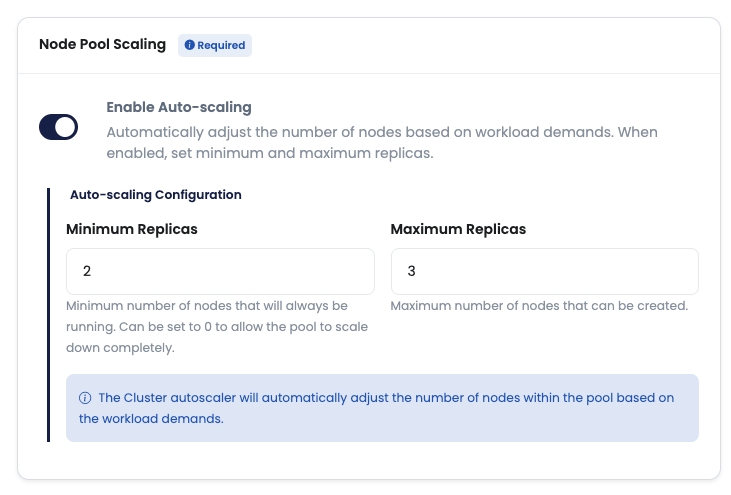
Configure Kubernetes Node Pool autoscaling
Manage Node Allocatable
Enable automatic management of node allocatable resources to ensure stable operation of system components.
- When enabled, the platform reserves capacity on each node for critical system daemons (kubelet, container runtime, CNI) and OS processes
- The reserved resources are subtracted from the node’s allocatable values so that Pods do not overcommit the node
- Reservations scale with the node size to maintain predictable headroom
This feature helps prevent resource starvation of system components under heavy workload pressure and improves scheduling accuracy.
Upgrade Strategy
Choose how this node pool applies Kubernetes version upgrades:
- Auto: Automatically upgrades the node pool to match the cluster control plane version when a new version is applied to the cluster
- Manual: Upgrades occur only when explicitly triggered; use this for tighter change control windows. This means the user is responsible for upgrading the node pool by changing it’s version.
During upgrades, nodes are cordoned and drained respecting PodDisruptionBudgets (PDBs). Workloads are rescheduled to healthy nodes before a node is replaced.
Security Groups for Node Pools
Security groups act as virtual firewalls for your Kubernetes node pool, controlling inbound and outbound traffic to the nodes. Node pools require security groups for network isolation. Security groups attached to node pools control access to the individual nodes and their workloads.
Define ingress rules to determine which traffic is allowed to access the Kubernetes nodes. Typical considerations include:
- Ensure nodes can communicate with the Kubernetes control plane (API server)
- Allow necessary traffic between nodes in the cluster (for example, CNI data plane and health ports). See the Cilium documentation for required ports: Cilium port requirements
- Consider pod-to-pod communication requirements and any exposure needed for Services of type
LoadBalancerorNodePort
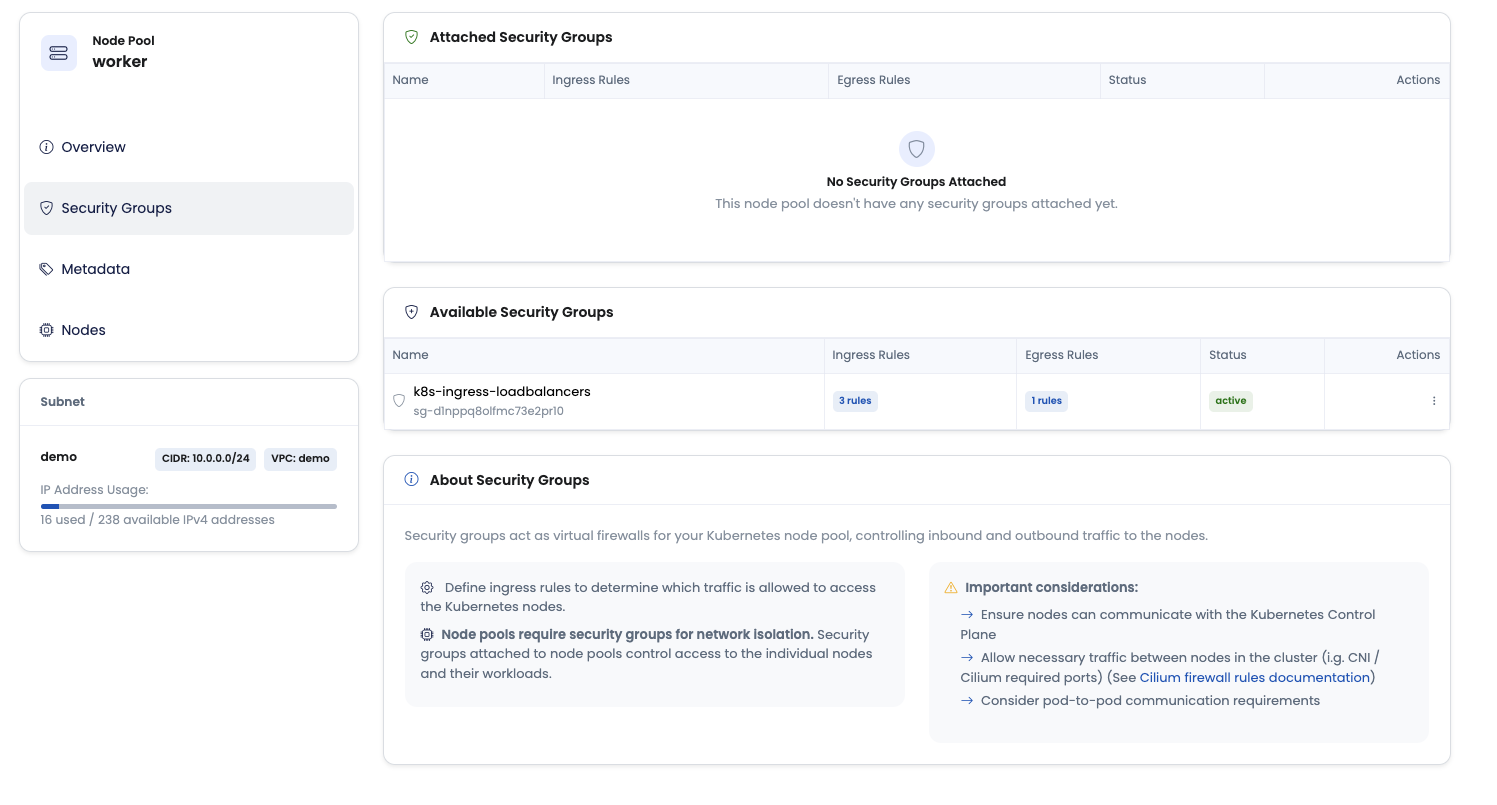
Configure Kubernetes Node Security Groups
For broader guidance on configuring rules, see: Working with Security Groups.
Node Labels in Thalassa Cloud
The Thalassa Cloud Controller Manager automatically assigns specific labels to nodes, which can be used for scheduling, node selection, and workload distribution.
Standard Node Labels
| Label | Example Value | Description |
|---|---|---|
k8s.thalassa.cloud/region | nl-1 | The region where the node is deployed. |
k8s.thalassa.cloud/zone | nl-1a | The availability zone of the node. |
kubernetes.io/hostname | node-1 | The unique hostname of the node. |
kubernetes.io/os | linux | The operating system of the node. |
kubernetes.io/arch | amd64 | The CPU architecture of the node. |
node.kubernetes.io/instance-type | pgp.large | The instance type of the node. |
k8s.thalassa.cloud/vpc | vpc-123456 | The VPC ID where the node is running. |
k8s.thalassa.cloud/subnet | subnet-abc123 | The subnet ID assigned to the node. |
k8s.thalassa.cloud/node-pool | general-pool | The node pool to which the node belongs. |
These labels can be used in node affinity rules and taints/tolerations to ensure workloads are scheduled appropriately.
Example: Scheduling a Pod on a Specific Node Type
To ensure a workload runs on a node of type pgp.large, use the following nodeSelector:
apiVersion: v1
kind: Pod
metadata:
name: large-workload
spec:
nodeSelector:
node.kubernetes.io/instance-type: "pgp.large"
containers:
- name: app
image: my-app:latestManaging Nodes
Viewing Nodes in a Cluster
To list all nodes in your Kubernetes cluster:
kubectl get nodesTo get more details about a specific node:
kubectl describe node <node-name>Taints and Tolerations
Taints prevent workloads from being scheduled on certain nodes unless they have a matching toleration.
To add a taint to a node:
kubectl taint nodes node-1 key=value:NoScheduleTo allow a pod to tolerate this taint:
apiVersion: v1
kind: Pod
metadata:
name: tolerant-pod
spec:
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
containers:
- name: app
image: my-app:latestMonitoring and Troubleshooting Nodes
Checking Node Resource Usage
kubectl top nodesViewing Node Events
kubectl get events --field-selector involvedObject.kind=NodeSummary
Thalassa Cloud provides flexible, scalable, and optimized Kubernetes nodes, automatically provisioned with labels, monitoring, and debugging support.
Key Takeaways:
- Nodes are virtual machines running workloads in a cluster.
- Cloud Controller Manager assigns predefined labels for scheduling and workload placement.
- Taints and tolerations control where workloads can run.
- Monitoring tools provide insights into node health and performance.